Cloudera CCA-500 Braindumps 2021
It is more faster and easier to pass the by using . Immediate access to the and find the same core area with professionally verified answers, then PASS your exam with a high score now.
Online CCA-500 free questions and answers of New Version:
NEW QUESTION 1
You want to understand more about how users browse your public website. For example, you want to know which pages they visit prior to placing an order. You have a server farm of 200 web servers hosting your website. Which is the most efficient process to gather these web server across logs into your Hadoop cluster analysis?
- A. Sample the web server logs web servers and copy them into HDFS using curl
- B. Ingest the server web logs into HDFS using Flume
- C. Channel these clickstreams into Hadoop using Hadoop Streaming
- D. Import all user clicks from your OLTP databases into Hadoop using Sqoop
- E. Write a MapReeeduce job with the web servers for mappers and the Hadoop cluster nodes for reducers
Answer: B
Explanation: Apache Flume is a service for streaming logs into Hadoop.
Apache Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of streaming data into the Hadoop Distributed File System (HDFS). It has a simple and flexible architecture based on streaming data flows; and is robust and fault tolerant with tunable reliability mechanisms for failover and recovery.
NEW QUESTION 2
Table schemas in Hive are:
- A. Stored as metadata on the NameNode
- B. Stored along with the data in HDFS
- C. Stored in the Metadata
- D. Stored in ZooKeeper
Answer: B
NEW QUESTION 3
You have a Hadoop cluster HDFS, and a gateway machine external to the cluster from which clients submit jobs. What do you need to do in order to run Impala on the cluster and submit jobs from the command line of the gateway machine?
- A. Install the impalad daemon statestored daemon, and daemon on each machine in the cluster, and the impala shell on your gateway machine
- B. Install the impalad daemon, the statestored daemon, the catalogd daemon, and the impala shell on your gateway machine
- C. Install the impalad daemon and the impala shell on your gateway machine, and the statestored daemon and catalogd daemon on one of the nodes in the cluster
- D. Install the impalad daemon on each machine in the cluster, the statestored daemon and catalogd daemon on one machine in the cluster, and the impala shell on your gateway machine
- E. Install the impalad daemon, statestored daemon, and catalogd daemon on each machine in the cluster and on the gateway node
Answer: D
NEW QUESTION 4
Given:
You want to clean up this list by removing jobs where the State is KILLED. What command you enter?
- A. Yarn application –refreshJobHistory
- B. Yarn application –kill application_1374638600275_0109
- C. Yarn rmadmin –refreshQueue
- D. Yarn rmadmin –kill application_1374638600275_0109
Answer: B
Explanation: Reference:http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1-latest/bk_using-apache-hadoop/content/common_mrv2_commands.html
NEW QUESTION 5
You decide to create a cluster which runs HDFS in High Availability mode with automatic failover, using Quorum Storage. What is the purpose of ZooKeeper in such a configuration?
- A. It only keeps track of which NameNode is Active at any given time
- B. It monitors an NFS mount point and reports if the mount point disappears
- C. It both keeps track of which NameNode is Active at any given time, and manages the Edits fil
- D. Which is a log of changes to the HDFS filesystem
- E. If only manages the Edits file, which is log of changes to the HDFS filesystem
- F. Clients connect to ZooKeeper to determine which NameNode is Active
Answer: A
Explanation: Reference: Reference:http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/PDF/CDH4-High-Availability-Guide.pdf(page 15)
NEW QUESTION 6
A user comes to you, complaining that when she attempts to submit a Hadoop job, it fails. There is a Directory in HDFS named /data/input. The Jar is named j.jar, and the driver class is named DriverClass.
She runs the command:
Hadoop jar j.jar DriverClass /data/input/data/output The error message returned includes the line:
PriviligedActionException as:training (auth:SIMPLE) cause:org.apache.hadoop.mapreduce.lib.input.invalidInputException:
Input path does not exist: file:/data/input What is the cause of the error?
- A. The user is not authorized to run the job on the cluster
- B. The output directory already exists
- C. The name of the driver has been spelled incorrectly on the command line
- D. The directory name is misspelled in HDFS
- E. The Hadoop configuration files on the client do not point to the cluster
Answer: A
NEW QUESTION 7
Cluster Summary:
45 files and directories, 12 blocks = 57 total. Heap size is 15.31 MB/193.38MB(7%)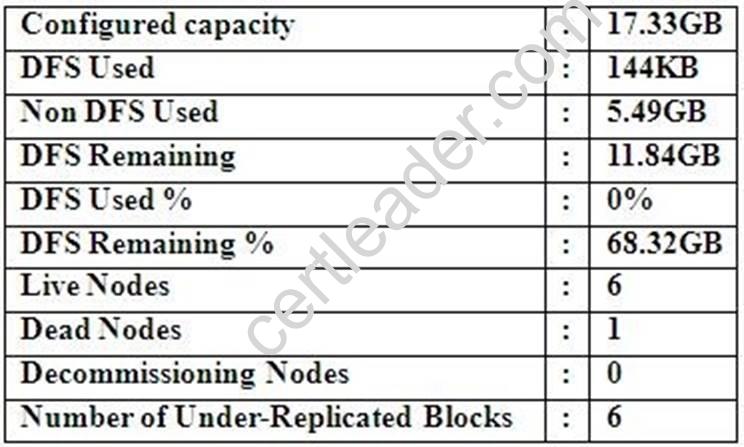
Refer to the above screenshot.
You configure a Hadoop cluster with seven DataNodes and on of your monitoring UIs displays the details shown in the exhibit.
What does the this tell you?
- A. The DataNode JVM on one host is not active
- B. Because your under-replicated blocks count matches the Live Nodes, one node is dead, and your DFS Used % equals 0%, you can’t be certain that your cluster has all the data you’ve written it.
- C. Your cluster has lost all HDFS data which had bocks stored on the dead DatNode
- D. The HDFS cluster is in safe mode
Answer: A
NEW QUESTION 8
Your company stores user profile records in an OLTP databases. You want to join these records with web server logs you have already ingested into the Hadoop file system. What is the best way to obtain and ingest these user records?
- A. Ingest with Hadoop streaming
- B. Ingest using Hive’s IQAD DATA command
- C. Ingest with sqoop import
- D. Ingest with Pig’s LOAD command
- E. Ingest using the HDFS put command
Answer: C
NEW QUESTION 9
You are configuring a server running HDFS, MapReduce version 2 (MRv2) on YARN running Linux. How must you format underlying file system of each DataNode?
- A. They must be formatted as HDFS
- B. They must be formatted as either ext3 or ext4
- C. They may be formatted in any Linux file system
- D. They must not be formatted - - HDFS will format the file system automatically
Answer: B
NEW QUESTION 10
You are running a Hadoop cluster with MapReduce version 2 (MRv2) on YARN. You consistently see that MapReduce map tasks on your cluster are running slowly because of excessive garbage collection of JVM, how do you increase JVM heap size property to 3GB to optimize performance?
- A. yarn.application.child.java.opts=-Xsx3072m
- B. yarn.application.child.java.opts=-Xmx3072m
- C. mapreduce.map.java.opts=-Xms3072m
- D. mapreduce.map.java.opts=-Xmx3072m
Answer: C
Explanation: Reference:http://hortonworks.com/blog/how-to-plan-and-configure-yarn-in-hdp-2-0/
NEW QUESTION 11
Assume you have a file named foo.txt in your local directory. You issue the following three commands:
Hadoop fs –mkdir input
Hadoop fs –put foo.txt input/foo.txt
Hadoop fs –put foo.txt input
What happens when you issue the third command?
- A. The write succeeds, overwriting foo.txt in HDFS with no warning
- B. The file is uploaded and stored as a plain file named input
- C. You get a warning that foo.txt is being overwritten
- D. You get an error message telling you that foo.txt already exists, and asking you if you would like to overwrite it.
- E. You get a error message telling you that foo.txt already exist
- F. The file is not written to HDFS
- G. You get an error message telling you that input is not a directory
- H. The write silently fails
Answer: CE
NEW QUESTION 12
Your cluster’s mapred-start.xml includes the following parameters
<name>mapreduce.map.memory.mb</name>
<value>4096</value>
<name>mapreduce.reduce.memory.mb</name>
<value>8192</value>
And any cluster’s yarn-site.xml includes the following parameters
<name>yarn.nodemanager.vmen-pmen-ration</name>
<value>2.1</value>
What is the maximum amount of virtual memory allocated for each map task before YARN will kill its Container?
- A. 4 GB
- B. 17.2 GB
- C. 8.9 GB
- D. 8.2 GB
- E. 24.6 GB
Answer: D
NEW QUESTION 13
You are running Hadoop cluster with all monitoring facilities properly configured. Which scenario will go undeselected?
- A. HDFS is almost full
- B. The NameNode goes down
- C. A DataNode is disconnected from the cluster
- D. Map or reduce tasks that are stuck in an infinite loop
- E. MapReduce jobs are causing excessive memory swaps
Answer: B
NEW QUESTION 14
On a cluster running CDH 5.0 or above, you use the hadoop fs –put command to write a 300MB file into a previously empty directory using an HDFS block size of 64 MB. Just after this command has finished writing 200 MB of this file, what would another use see when they look in directory?
- A. The directory will appear to be empty until the entire file write is completed on the cluster
- B. They will see the file with a ._COPYING_ extension on its nam
- C. If they view the file, they will see contents of the file up to the last completed block (as each 64MB block is written, that block becomes available)
- D. They will see the file with a ._COPYING_ extension on its nam
- E. If they attempt to view the file, they will get a ConcurrentFileAccessException until the entire file write is completed on the cluster
- F. They will see the file with its original nam
- G. If they attempt to view the file, they will get a ConcurrentFileAccessException until the entire file write is completed on the cluster
Answer: B
NEW QUESTION 15
Which process instantiates user code, and executes map and reduce tasks on a cluster running MapReduce v2 (MRv2) on YARN?
- A. NodeManager
- B. ApplicationMaster
- C. TaskTracker
- D. JobTracker
- E. NameNode
- F. DataNode
- G. ResourceManager
Answer: A
NEW QUESTION 16
Each node in your Hadoop cluster, running YARN, has 64GB memory and 24 cores. Your yarn.site.xml has the following configuration:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>32768</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>12</value>
</property>
You want YARN to launch no more than 16 containers per node. What should you do?
- A. Modify yarn-site.xml with the following property:<name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value>
- B. Modify yarn-sites.xml with the following property:<name>yarn.scheduler.minimum-allocation-mb</name><value>4096</value>
- C. Modify yarn-site.xml with the following property:<name>yarn.nodemanager.resource.cpu-vccores</name>
- D. No action is needed: YARN’s dynamic resource allocation automatically optimizes the node memory and cores
Answer: A
NEW QUESTION 17
For each YARN job, the Hadoop framework generates task log file. Where are Hadoop task log files stored?
- A. Cached by the NodeManager managing the job containers, then written to a log directory on the NameNode
- B. Cached in the YARN container running the task, then copied into HDFS on job completion
- C. In HDFS, in the directory of the user who generates the job
- D. On the local disk of the slave mode running the task
Answer: D
NEW QUESTION 18
You’re upgrading a Hadoop cluster from HDFS and MapReduce version 1 (MRv1) to one running HDFS and MapReduce version 2 (MRv2) on YARN. You want to set and enforce version 1 (MRv1) to one running HDFS and MapReduce version 2 (MRv2) on YARN. You want to set and enforce a block size of 128MB for all new files written to the cluster after upgrade. What should you do?
- A. You cannot enforce this, since client code can always override this value
- B. Set dfs.block.size to 128M on all the worker nodes, on all client machines, and on the NameNode, and set the parameter to final
- C. Set dfs.block.size to 128 M on all the worker nodes and client machines, and set the parameter to fina
- D. You do not need to set this value on the NameNode
- E. Set dfs.block.size to 134217728 on all the worker nodes, on all client machines, and on the NameNode, and set the parameter to final
- F. Set dfs.block.size to 134217728 on all the worker nodes and client machines, and set the parameter to fina
- G. You do not need to set this value on the NameNode
Answer: C
P.S. Easily pass CCA-500 Exam with 60 Q&As Simply pass Dumps & pdf Version, Welcome to Download the Newest Simply pass CCA-500 Dumps: https://www.simply-pass.com/Cloudera-exam/CCA-500-dumps.html (60 New Questions)