Microsoft DP-200 Braindump 2021
Best Quality of DP-200 test preparation materials and preparation exams for Microsoft certification for customers, Real Success Guaranteed with Updated DP-200 pdf dumps vce Materials. 100% PASS Implementing an Azure Data Solution exam Today!
Check DP-200 free dumps before getting the full version:
NEW QUESTION 1
You need to set up access to Azure SQL Database for Tier 7 and Tier 8 partners.
Which three actions should you perform in sequence? To answer, move the appropriate three actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Tier 7 and 8 data access is constrained to single endpoints managed by partners for access Step 1: Set the Allow Azure Services to Access Server setting to Disabled
Set Allow access to Azure services to OFF for the most secure configuration.
By default, access through the SQL Database firewall is enabled for all Azure services, under Allow access to Azure services. Choose OFF to disable access for all Azure services.
Note: The firewall pane has an ON/OFF button that is labeled Allow access to Azure services. The ON setting allows communications from all Azure IP addresses and all Azure subnets. These Azure IPs or subnets might not be owned by you. This ON setting is probably more open than you want your SQL Database to be. The virtual network rule feature offers much finer granular control.
Step 2: In the Azure portal, create a server firewall rule Set up SQL Database server firewall rules
Server-level IP firewall rules apply to all databases within the same SQL Database server. To set up a server-level firewall rule: In Azure portal, select SQL databases from the left-hand menu, and select your database on the SQL databases page.
In Azure portal, select SQL databases from the left-hand menu, and select your database on the SQL databases page. On the Overview page, select Set server firewall. The Firewall settings page for the database server opens.
On the Overview page, select Set server firewall. The Firewall settings page for the database server opens.
Step 3: Connect to the database and use Transact-SQL to create a database firewall rule
Database-level firewall rules can only be configured using Transact-SQL (T-SQL) statements, and only after you've configured a server-level firewall rule.
To setup a database-level firewall rule: In Object Explorer, right-click the database and select New Query.EXECUTE sp_set_database_firewall_rule N'Example DB Rule','0.0.0.4','0.0.0.4'; On the toolbar, select Execute to create the firewall rule. References:
In Object Explorer, right-click the database and select New Query.EXECUTE sp_set_database_firewall_rule N'Example DB Rule','0.0.0.4','0.0.0.4'; On the toolbar, select Execute to create the firewall rule. References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-security-tutorial
NEW QUESTION 2
You need to develop a pipeline for processing data. The pipeline must meet the following requirements.
•Scale up and down resources for cost reduction.
•Use an in-memory data processing engine to speed up ETL and machine learning operations.
•Use streaming capabilities.
•Provide the ability to code in SQL, Python, Scala, and R.
•Integrate workspace collaboration with Git. What should you use?
- A. HDInsight Spark Cluster
- B. Azure Stream Analytics
- C. HDInsight Hadoop Cluster
- D. Azure SQL Data Warehouse
Answer: B
NEW QUESTION 3
You are a data architect. The data engineering team needs to configure a synchronization of data between an on-premises Microsoft SQL Server database to Azure SQL Database.
Ad-hoc and reporting queries are being overutilized the on-premises production instance. The synchronization process must:
Perform an initial data synchronization to Azure SQL Database with minimal downtime Perform bi-directional data synchronization after initial synchronization
You need to implement this synchronization solution. Which synchronization method should you use?
- A. transactional replication
- B. Data Migration Assistant (DMA)
- C. backup and restore
- D. SQL Server Agent job
- E. Azure SQL Data Sync
Answer: E
Explanation:
SQL Data Sync is a service built on Azure SQL Database that lets you synchronize the data you select bi-directionally across multiple SQL databases and SQL Server instances.
With Data Sync, you can keep data synchronized between your on-premises databases and Azure SQL databases to enable hybrid applications.
Compare Data Sync with Transactional Replication
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-sync-data
NEW QUESTION 4
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You need to configure data encryption for external applications. Solution:
1. Access the Always Encrypted Wizard in SQL Server Management Studio
2. Select the column to be encrypted
3. Set the encryption type to Randomized
4. Configure the master key to use the Windows Certificate Store
5. Validate configuration results and deploy the solution Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Use the Azure Key Vault, not the Windows Certificate Store, to store the master key.
Note: The Master Key Configuration page is where you set up your CMK (Column Master Key) and select the key store provider where the CMK will be stored. Currently, you can store a CMK in the Windows certificate store, Azure Key Vault, or a hardware security module (HSM).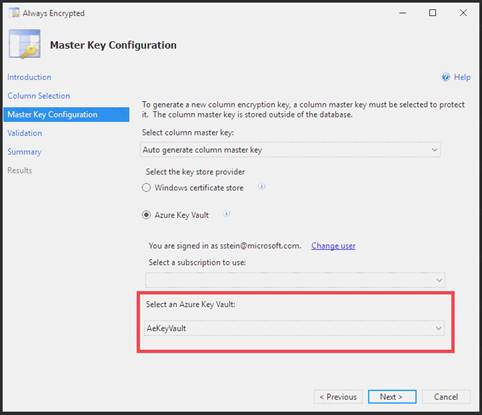
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-always-encrypted-azure-key-vault
NEW QUESTION 5
You are a data engineer implementing a lambda architecture on Microsoft Azure. You use an open-source big data solution to collect, process, and maintain data. The analytical data store performs poorly.
You must implement a solution that meets the following requirements:  Provide data warehousing Reduce ongoing management activities
Provide data warehousing Reduce ongoing management activities Deliver SQL query responses in less than one second
Deliver SQL query responses in less than one second
You need to create an HDInsight cluster to meet the requirements. Which type of cluster should you create?
- A. Interactive Query
- B. Apache Hadoop
- C. Apache HBase
- D. Apache Spark
Answer: D
Explanation:
Lambda Architecture with Azure:
Azure offers you a combination of following technologies to accelerate real-time big data analytics: Azure Cosmos DB, a globally distributed and multi-model database service. Apache Spark for Azure HDInsight, a processing framework that runs large-scale data analytics applications.The Spark to Azure Cosmos DB Connector
Note: Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch processing and stream processing methods, and minimizing the latency involved in querying big data.
References:
https://sqlwithmanoj.com/2021/02/16/what-is-lambda-architecture-and-what-azure-offers-with-its-new-cosmos-
NEW QUESTION 6
You manage a financial computation data analysis process. Microsoft Azure virtual machines (VMs) run the process in daily jobs, and store the results in virtual hard drives (VHDs.)
The VMs product results using data from the previous day and store the results in a snapshot of the VHD. When a new month begins, a process creates a new VHD.
You must implement the following data retention requirements:  Daily results must be kept for 90 days
Daily results must be kept for 90 days Data for the current year must be available for weekly reports Data from the previous 10 years must be stored for auditing purposes Data required for an audit must be produced within 10 days of a request. You need to enforce the data retention requirements while minimizing cost.
Data for the current year must be available for weekly reports Data from the previous 10 years must be stored for auditing purposes Data required for an audit must be produced within 10 days of a request. You need to enforce the data retention requirements while minimizing cost.
How should you configure the lifecycle policy? To answer, drag the appropriate JSON segments to the correct locations. Each JSON segment may be used once, more than once, or not at all. You may need to drag the split bat between panes or scroll to view content.
NOTE: Each correct selection is worth one point.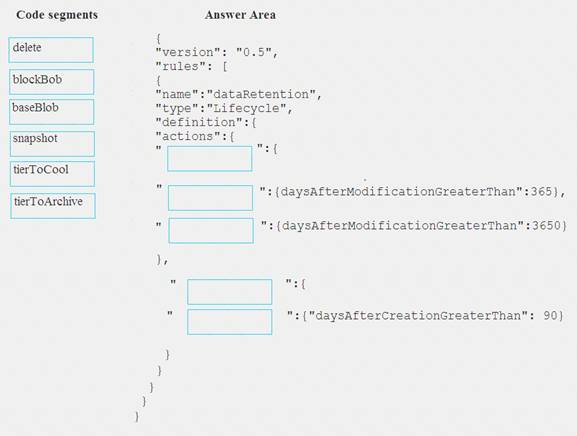
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
The Set-AzStorageAccountManagementPolicy cmdlet creates or modifies the management policy of an Azure Storage account.
Example: Create or update the management policy of a Storage account with ManagementPolicy rule objects.
Action -BaseBlobAction Delete -daysAfterModificationGreaterThan 100
PS C:>$action1 = Add-AzStorageAccountManagementPolicyAction -InputObject $action1 -BaseBlobAction TierToArchive -daysAfterModificationGreaterThan 50
PS C:>$action1 = Add-AzStorageAccountManagementPolicyAction -InputObject $action1 -BaseBlobAction TierToCool -daysAfterModificationGreaterThan 30
PS C:>$action1 = Add-AzStorageAccountManagementPolicyAction -InputObject $action1 -SnapshotAction Delete -daysAfterCreationGreaterThan 100
PS C:>$filter1 = New-AzStorageAccountManagementPolicyFilter -PrefixMatch ab,cd
PS C:>$rule1 = New-AzStorageAccountManagementPolicyRule -Name Test -Action $action1 -Filter $filter1
PS C:>$action2 = Add-AzStorageAccountManagementPolicyAction -BaseBlobAction Delete
-daysAfterModificationGreaterThan 100
PS C:>$filter2 = New-AzStorageAccountManagementPolicyFilter References:
https://docs.microsoft.com/en-us/powershell/module/az.storage/set-azstorageaccountmanagementpolicy
NEW QUESTION 7
A company uses Azure SQL Database to store sales transaction data. Field sales employees need an offline copy of the database that includes last year’s sales on their laptops when there is no internet connection available.
You need to create the offline export copy.
Which three options can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Export to a BACPAC file by using Azure Cloud Shell, and save the file to an Azure storage account
- B. Export to a BACPAC file by using SQL Server Management Studi
- C. Save the file to an Azure storage account
- D. Export to a BACPAC file by using the Azure portal
- E. Export to a BACPAC file by using Azure PowerShell and save the file locally
- F. Export to a BACPAC file by using the SqlPackage utility
Answer: BCE
NEW QUESTION 8
You need to provision the polling data storage account.
How should you configure the storage account? To answer, drag the appropriate Configuration Value to the correct Setting. Each Configuration Value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.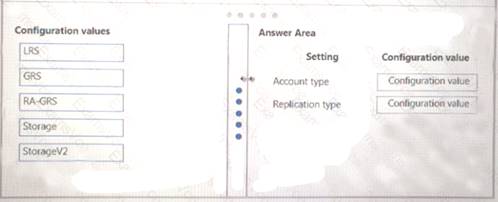
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 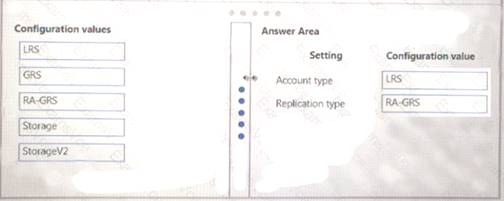
NEW QUESTION 9
A company is planning to use Microsoft Azure Cosmos DB as the data store for an application. You have the following Azure CLI command:
az cosmosdb create -–name "cosmosdbdev1" –-resource-group "rgdev"
You need to minimize latency and expose the SQL API. How should you complete the command? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Eventual
With Azure Cosmos DB, developers can choose from five well-defined consistency models on the consistency spectrum. From strongest to more relaxed, the models include strong, bounded staleness, session, consistent prefix, and eventual consistency.
The following image shows the different consistency levels as a spectrum.
Box 2: GlobalDocumentDB
Select Core(SQL) to create a document database and query by using SQL syntax.
Note: The API determines the type of account to create. Azure Cosmos DB provides five APIs: Core(SQL) and MongoDB for document databases, Gremlin for graph databases, Azure Table, and Cassandra.
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels https://docs.microsoft.com/en-us/azure/cosmos-db/create-sql-api-dotnet
NEW QUESTION 10
Your company uses several Azure HDInsight clusters.
The data engineering team reports several errors with some application using these clusters. You need to recommend a solution to review the health of the clusters.
What should you include in you recommendation?
- A. Azure Automation
- B. Log Analytics
- C. Application Insights
Answer: C
NEW QUESTION 11
You need to ensure that phone-based poling data can be analyzed in the PollingData database. How should you configure Azure Data Factory?
- A. Use a tumbling schedule trigger
- B. Use an event-based trigger
- C. Use a schedule trigger
- D. Use manual execution
Answer: C
Explanation:
When creating a schedule trigger, you specify a schedule (start date, recurrence, end date etc.) for the trigger, and associate with a Data Factory pipeline.
Scenario:
All data migration processes must use Azure Data Factory
All data migrations must run automatically during non-business hours References:
https://docs.microsoft.com/en-us/azure/data-factory/how-to-create-schedule-trigger
NEW QUESTION 12
A company uses Microsoft Azure SQL Database to store sensitive company data. You encrypt the data and only allow access to specified users from specified locations.
You must monitor data usage, and data copied from the system to prevent data leakage.
You need to configure Azure SQL Database to email a specific user when data leakage occurs.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 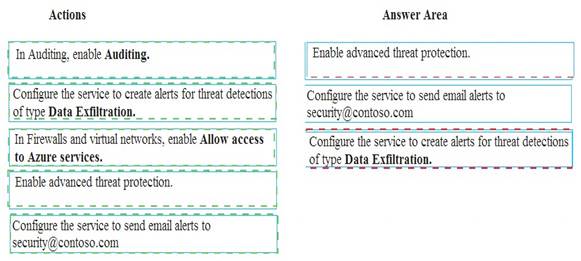
NEW QUESTION 13
You implement 3 Azure SQL Data Warehouse instance.
You plan to migrate the largest fact table to Azure SQL Data Warehouse The table resides on Microsoft SQL Server on-premises and e 10 terabytes (TB) in size.
Incoming queues use the primary key Sale Key column to retrieve data as displayed in the following table: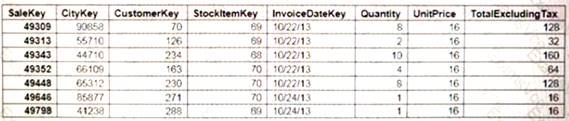
You need to distribute the fact table across multiple nodes to optimize performance of the table. Which technology should you use?
- A. hash distributed table with clustered ColumnStore index
- B. hash distributed table with clustered index
- C. heap table with distribution replicate
- D. round robin distributed table with clustered index
- E. round robin distributed table with clustered ColumnStore index
Answer: A
NEW QUESTION 14
You need to ensure that phone-based polling data can be analyzed in the PollingData database.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer are and arrange them in the correct order.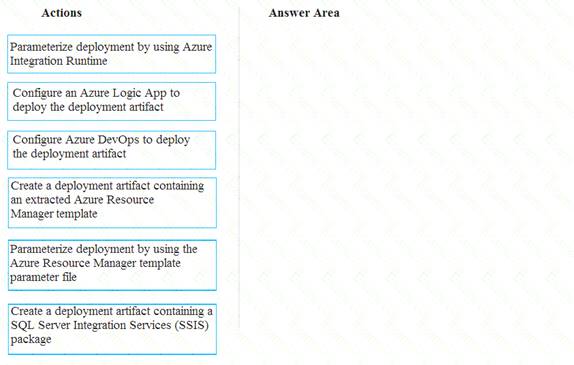
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 
Scenario:
All deployments must be performed by using Azure DevOps. Deployments must use templates used in multiple environments
No credentials or secrets should be used during deployments
NEW QUESTION 15
Your company uses Azure SQL Database and Azure Blob storage.
All data at rest must be encrypted by using the company's own key. The solution must minimize administrative effort and the impact to applications which use the database.
You need to configure security.
What should you implement? To answer, select the appropriate option in the answer area. NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 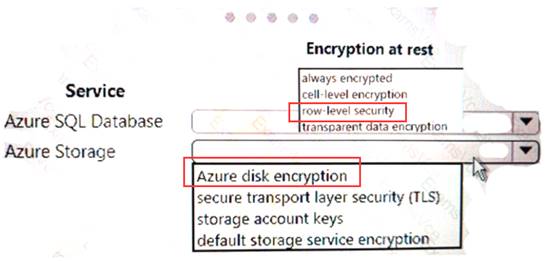
NEW QUESTION 16
You develop data engineering solutions for a company.
You need to ingest and visualize real-time Twitter data by using Microsoft Azure.
Which three technologies should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Event Grid topic
- B. Azure Stream Analytics Job that queries Twitter data from an Event Hub
- C. Azure Stream Analytics Job that queries Twitter data from an Event Grid
- D. Logic App that sends Twitter posts which have target keywords to Azure
- E. Event Grid subscription
- F. Event Hub instance
Answer: BDF
Explanation:
You can use Azure Logic apps to send tweets to an event hub and then use a Stream Analytics job to read from event hub and send them to PowerBI.
References:
https://community.powerbi.com/t5/Integrations-with-Files-and/Twitter-streaming-analytics-step-by-step/td-p/95
NEW QUESTION 17
You need to process and query ingested Tier 9 data.
Which two options should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Azure Notification Hub
- B. Transact-SQL statements
- C. Azure Cache for Redis
- D. Apache Kafka statements
- E. Azure Event Grid
- F. Azure Stream Analytics
Answer: EF
Explanation:
Event Hubs provides a Kafka endpoint that can be used by your existing Kafka based applications as an alternative to running your own Kafka cluster.
You can stream data into Kafka-enabled Event Hubs and process it with Azure Stream Analytics, in the following steps: Create a Kafka enabled Event Hubs namespace. Create a Kafka client that sends messages to the event hub. Create a Stream Analytics job that copies data from the event hub into an Azure blob storage. Scenario:
Tier 9 reporting must be moved to Event Hubs, queried, and persisted in the same Azure region as the company’s main office
References:
https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-kafka-stream-analytics
NEW QUESTION 18
You need to mask tier 1 data. Which functions should you use? To answer, select the appropriate option in the answer area.
NOTE: Each correct selection is worth one point.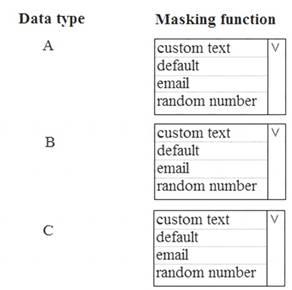
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
A: Default
Full masking according to the data types of the designated fields.
For string data types, use XXXX or fewer Xs if the size of the field is less than 4 characters (char, nchar, varchar, nvarchar, text, ntext).
B: email
C: Custom text
Custom StringMasking method which exposes the first and last letters and adds a custom padding string in the middle. prefix,[padding],suffix
Tier 1 Database must implement data masking using the following masking logic:
References:
https://docs.microsoft.com/en-us/sql/relational-databases/security/dynamic-data-masking
NEW QUESTION 19
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You need to implement diagnostic logging for Data Warehouse monitoring. Which log should you use?
- A. RequestSteps
- B. DmsWorkers
- C. SqlRequests
- D. ExecRequests
Answer: C
Explanation:
Scenario:
The Azure SQL Data Warehouse cache must be monitored when the database is being used.
References:
https://docs.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-sql-r
NEW QUESTION 20
You manage a process that performs analysis of daily web traffic logs on an HDInsight cluster. Each of 250 web servers generates approximately gigabytes (GB) of log data each day. All log data is stored in a single folder in Microsoft Azure Data Lake Storage Gen 2.
You need to improve the performance of the process.
Which two changes should you make? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A. Combine the daily log files for all servers into one file
- B. Increase the value of the mapreduce.map.memory parameter
- C. Move the log files into folders so that each day’s logs are in their own folder
- D. Increase the number of worker nodes
- E. Increase the value of the hive.tez.container.size parameter
Answer: AC
Explanation:
A: Typically, analytics engines such as HDInsight and Azure Data Lake Analytics have a per-file overhead. If you store your data as many small files, this can negatively affect performance. In general, organize your data into larger sized files for better performance (256MB to 100GB in size). Some engines and applications might have trouble efficiently processing files that are greater than 100GB in size.
C: For Hive workloads, partition pruning of time-series data can help some queries read only a subset of the data which improves performance.
Those pipelines that ingest time-series data, often place their files with a very structured naming for files and folders. Below is a very common example we see for data that is structured by date:
DataSetYYYYMMDDdatafile_YYYY_MM_DD.tsv
Notice that the datetime information appears both as folders and in the filename. References:
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-performance-tuning-guidance
NEW QUESTION 21
......
Recommend!! Get the Full DP-200 dumps in VCE and PDF From Simply pass, Welcome to Download: https://www.simply-pass.com/Microsoft-exam/DP-200-dumps.html (New 88 Q&As Version)