Free 70-475 Braindumps 2021
Master the 70 475 exam content and be ready for exam day success quickly with this exam 70 475. We guarantee it!We make it a reality and give you real 70 475 exam in our Microsoft 70-475 braindumps. Latest 100% VALID exam 70 475 at below page. You can use our Microsoft 70-475 braindumps and pass your exam.
Free demo questions for Microsoft 70-475 Exam Dumps Below:
NEW QUESTION 1
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while the others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft Azure deployment that contains the following services:  Azure Data Lake Azure Cosmos DB Azure Data Factory Azure SQL Database
Azure Data Lake Azure Cosmos DB Azure Data Factory Azure SQL Database
You load several types of data to Azure Data Lake.
You need to load data from Azure SQL Database to Azure Data Lake. Solution: You use the AzCopy utility.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
Explanation: Note: You can use the Copy Activity in Azure Data Factory to copy data to and from Azure Data Lake Storage Gen1 (previously known as Azure Data Lake Store). Azure SQL database is supported as source.
References: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-data-lake-store
NEW QUESTION 2
You have raw data in Microsoft Azure Blob storage. Each data file is 10 KB and is the XML format. You identify the following requirements for the data: The data must be converted into a flat data structure by using a C# MapReduce job. The data must be moved to an Azure SQL database, which will then be used to visualize the data. Additional stored procedures must run against the data once the data is in the database.
You need to create the workflow for the Azure Data Factory pipeline.
Which activity type should you use for each requirement? To answer, drag the appropriate workflow components to the correct requirements. Each workflow component may be used once, more than once, or not at all. You may need to drag the split bar between the panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: Box 1: HDinsightMapReduce
The HDInsight MapReduce activity in a Data Factory pipeline invokes MapReduce program on your own or on-demand HDInsight cluster.
Box 2: HDInsightStreaming
Box 3: SQLServerStoredProcedure
NEW QUESTION 3
You manage a Microsoft Azure HDInsight Hadoop cluster. All of the data for the cluster is stored in Azure Premium Storage.
You need to prevent all users from accessing the data directly. The solution must allow only the HDInsight service to access the data.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation: 1. Create Shared Access Signature policy2. Save the SAS policy token, storage account name, and container name. These values are used when associating the storage account with your HDInsight cluster.3. Update property of core-site4. Maintenance mode5. Restart all
serviceshttps://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-storage-sharedaccesssignature-permissions
NEW QUESTION 4
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the states goals. Some question sets might have more than one correct solution, while the others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to implement a new data warehouse.
You have the following information regarding the data warehouse: The first data files for the data warehouse will be available in a few days. Most queries that will be executed against the data warehouse are ad-hoc. The schemas of data files that will be loaded to the data warehouse change often. One month after the planned implementation, the data warehouse will contain 15 TB of data. You need to recommend a database solution to support the planned implementation.
Solution: You recommend an Apache Spark system. Does this meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 5
Your company has two Microsoft Azure SQL databases named db1 and db2.
You need to move data from a table in db1 to a table in db2 by using a pipeline in Azure Data Factory. You create an Azure Data Factory named ADF1.
Which two types Of objects Should you create In ADF1 to complete the pipeline? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. a linked service
- B. an Azure Service Bus
- C. sources and targets
- D. input and output I datasets
- E. transformations
Answer: AD
Explanation: You perform the following steps to create a pipeline that moves data from a source data store to a sink data store: Create linked services to link input and output data stores to your data factory. Create datasets to represent input and output data for the copy operation. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
NEW QUESTION 6
A Company named Fabrikam, Inc. has a web app. Millions of users visit the app daily.
Fabrikam performs a daily analysis of the previous day’s logs by scheduling the following Hive query.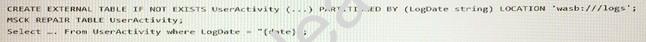
You need to recommend a solution to gather the log collections from the web app. What should you recommend?
- A. Generate a single directory that contains multiple files for each da
- B. Name the file by using the syntax of{date}_{randomsuffix}.txt.
- C. Generate a directory that is named by using the syntax of "LogDate={date}” and generate a set of files for that day.
- D. Generate a directory each day that has a single file.
- E. Generate a single directory that has a single file for each day.
Answer: B
NEW QUESTION 7
You are designing an Apache HBase cluster on Microsoft Azure HDInsight. You need to identify which nodes are required for the cluster.
Which three nodes should you identify? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Nimbus
- B. Zookeeper
- C. Region
- D. Supervisor
- E. Falcon
- F. Head
Answer: BCF
Explanation: https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-provision-linux-clusters
NEW QUESTION 8
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft Azure subscription that includes Azure Data Lake and Cognitive Services. An administrator plans to deploy an Azure Data Factory.
You need to ensure that the administrator can create the data factory. Solution: You add the user to the Data Factory Contributor role. Does this meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION 9
Your company has thousands of Internet-connected sensors.
You need to recommend a computing solution to perform a real-time analysis of the data generated by the sensors.
Which computing solution should you include in the recommendation?
- A. Microsoft Azure Stream Analytics
- B. Microsoft Azure Notification Hubs
- C. Microsoft Azure Cognitive Services
- D. a Microsoft Azure HDInsight HBase cluster
Answer: D
Explanation: HDInsight HBase is offered as a managed cluster that is integrated into the Azure environment. The clusters are configured to store data directly in Azure Storage or Azure Data Lake Store, which provides low latency and increased elasticity in performance and cost choices. This enables customers to build interactive websites
that work with large datasets, to build services that store sensor and telemetry data from millions of end points, and to analyze this data with Hadoop jobs. HBase and Hadoop are good starting points for big data project in Azure; in particular, they can enable real-time applications to work with large datasets.
NEW QUESTION 10
You need to recommend a data analysis solution for 20,000 Internet of Things (IoT) devices. The solution must meet the following requirements:
• Each device must be identified by using its own credentials.
• Each device must be able to route data to multiple endpoints.
• The solution must require the minimum amount of customized code. What should you recommend?
- A. Microsoft Azure Notification Hubs
- B. Microsoft Azure IoT Hub
- C. Microsoft Azure Service Bus
- D. Microsoft Azure Event Hubs
Answer: D
NEW QUESTION 11
You are designing a solution based on the lambda architecture.
You need to recommend which technology to use for the serving layer. What should you recommend?
- A. Apache Storm
- B. Kafka
- C. Microsoft Azure DocumentDB
- D. Apache Hadoop
Answer: C
Explanation: The Serving Layer is a bit more complicated in that it needs to be able to answer a single query request against two or more databases, processing platforms, and data storage devices. Apache Druid is an example of a cluster-based tool that can marry the Batch and Speed layers into a single answerable request.
NEW QUESTION 12
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while the others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft Azure deployment that contains the following services: Azure Data Lake Azure Cosmos DB Azure Data Factory Azure SQL Database
You load several types of data to Azure Data Lake.
You need to load data from Azure SQL Database to Azure Data Lake. Solution: You use the Azure Import/Export service.
Does this meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION 13
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions
will not appear in the review screen.
You plan to deploy a Microsoft Azure SQL data warehouse and a web application.
The data warehouse will ingest 5 TB of data from an on-premises Microsoft SQL Server database daily. The web application will query the data warehouse.
You need to design a solution to ingest data into the data warehouse.
Solution: You use the bcp utility to export CSV files from SQL Server and then to import the files to Azure SQL Data Warehouse.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
Explanation: If you need the best performance, then use PolyBase to import data into Azure SQL warehouse. References: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-migrate-data
NEW QUESTION 14
You implement DB2.
You need to configure the tables in DB2 to host the data from DB1. The solution must meet the requirements for DB2.
Which type of table and history table storage should you use for the tables? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.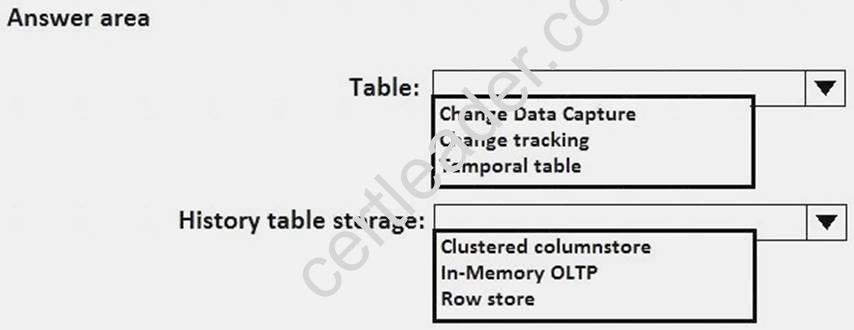
Answer:
Explanation: From Scenario: Relecloud plans to implement a data warehouse named DB2. Box 1: Temporal table
From Scenario:
Relecloud identifies the following requirements for DB2:
Users must be able to view previous versions of the data in DB2 by using aggregates. DB2 must be able to store more than 40 TB of data.
A system-versioned temporal table is a new type of user table in SQL Server 2021, designed to keep a full history of data changes and allow easy point in time analysis. A temporal table also contains a reference to another table with a mirrored schema. The system uses this table to automatically store the previous version of the row each time a row in the temporal table gets updated or deleted. This additional table is referred to as the history table, while the main table that stores current (actual) row versions is referred to as the current table or simply as the temporal table.
NEW QUESTION 15
You plan to design a solution to gather data from 5,000 sensors that are deployed to multiple machines. The sensors generate events that contain data on the health status of the machines.
You need to create a new Microsoft Azure event hub to collect the event data.
Which command should you run? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.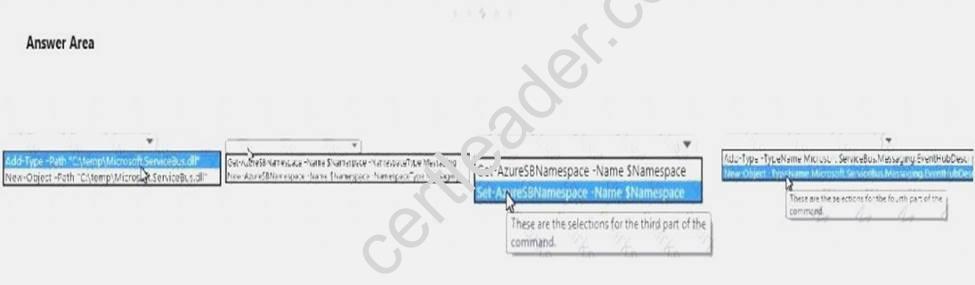
Answer:
Explanation: 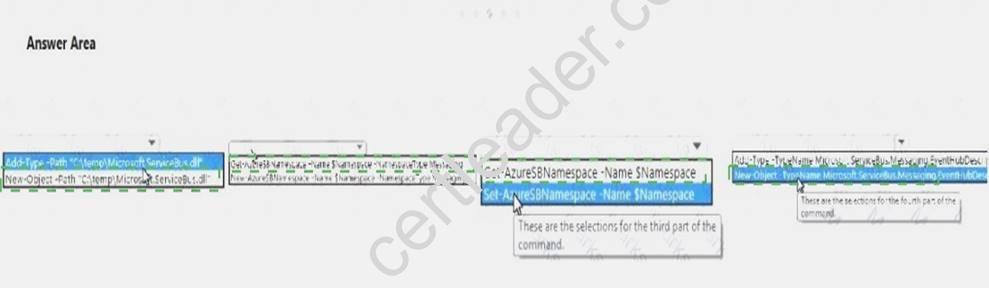
NEW QUESTION 16
You have an Apache Spark cluster on Microsoft Azure HDInsight for all analytics workloads.
You plan to build a Spark streaming application that processes events ingested by using Azure Event Hubs. You need to implement checkpointing in the Spark streaming application for high availability of the event
data.
In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation: 
NEW QUESTION 17
You need to implement a solution that meets the data refresh requirement for DB1.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.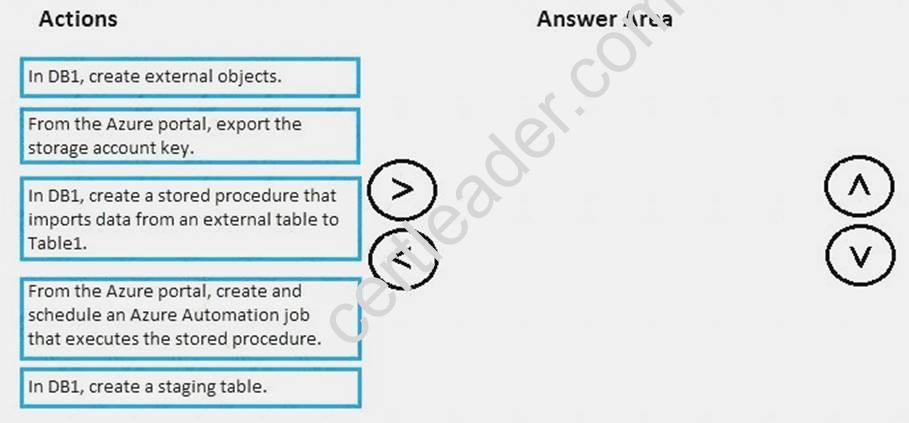
Answer:
Explanation: Azure Data Factory can be used to orchestrate the execution of stored procedures. This allows more complex pipelines to be created and extends Azure Data Factory's ability to leverage the computational power of SQL Data Warehouse.
From scenario:
Relecloud has a Microsoft SQL Server database named DB1 that stores information about the advertisers. DB1 is hosted on a Microsoft Azure virtual machine.
Relecloud identifies the following requirements for DB1: Data generated by the streaming analytics platform must be stored in DB1. The advertisers in DB1 must be stored in a table named Table1 and must be refreshed nightly.
Data generated by the streaming analytics platform must be stored in DB1. The advertisers in DB1 must be stored in a table named Table1 and must be refreshed nightly.
Topic 3, Litware, Inc
Overview
General Overview
Litware, Inc. is a company that manufactures personal devices to track physical activity and other health-related data.
Litware has a health tracking application that sends health-related data horn a user's personal device to Microsoft Azure.
Physical Locations
Litware has three development and commercial offices. The offices are located in the Untied States, Luxembourg, and India.
Litware products are sold worldwide. Litware has commercial representatives in more than 80 countries.
Existing Environment Environment
In addition to using desktop computers in all of the offices. Litware recently started using Microsoft Azure resources and services for both development and operations.
Litware has an Azure Machine Learning Solution.
Litware Health Tracking Application
Litware recently extended its platform to provide third-party companies with the ability to upload data from devices to Azure. The data can be aggregated across multiple devices to provide users with a comprehensive view of their global health activity.
While the upload from each device is small, potentially more than 100 million devices will upload data daily by using an Azure event hub.
Each health activity has a small amount of data, such as activity type, start date/time, and end date/time. Each activity is limited to a total of 3 KB and includes a customer Identification key.
In addition to the Litware health tracking application, the users' activities can be reported to Azure by using an open API.
Machine Learning Experiments
The developers at Litware perform Machine Learning experiments to recommend an appropriate health activity based on the past three activities of a user.
The Litware developers train a model to recommend the best activity for a user based on the hour of the day.
Requirements Planned Changes
Litware plans to extend the existing dashboard features so that health activities can be compared between the users based on age, gender, and geographic region.
Business Goals
Minimize the costs associated with transferring data from the event hub to Azure Storage.
Technical Requirements
Litware identities the following technical requirements:
Data from the devices must be stored from three years in a format that enables the fast processing of data fields and Filtering.
The third-party companies must be able to use the Litware Machine learning models to generate recommendations to their users by using a third-party application.
Any changes to the health tracking application must ensure that the Litware developers can run the experiments without interrupting or degrading the performance of the production environment.
Privacy Requirements
Activity tracking data must be available to all of the Litware developers for experimentation. The developers must be prevented from accessing the private information of the users.
Other Technical Requirements
When the Litware health tracking application asks users how they feel, their responses must be reported to Azure.
Topic 2, Mix Questions
NEW QUESTION 18
You have a Microsoft Azure SQL database that contains Personally Identifiable Information (PII).
To mitigate the PII risk, you need to ensure that data is encrypted while the data is at rest. The solution must minimize any changes to front-end applications.
What should you use?
- A. Transport Layer Security (TLS)
- B. transparent data encryption (TDE)
- C. a shared access signature (SAS)
- D. the ENCRYPTBYPASSPHRASE T-SQL function
Answer: B
Explanation: Transparent data encryption (TDE) helps protect Azure SQL Database, Azure SQL Managed Instance, and Azure Data Warehouse against the threat of malicious activity. It performs real-time encryption and decryption of the database, associated backups, and transaction log files at rest without requiring changes to the application.
References: https://docs.microsoft.com/en-us/azure/sql-database/transparent-data-encryption-azure-sql
P.S. Easily pass 70-475 Exam with 102 Q&As Certleader Dumps & pdf Version, Welcome to Download the Newest Certleader 70-475 Dumps: https://www.certleader.com/70-475-dumps.html (102 New Questions)