Microsoft 70-475 Study Guides 2021
It is more faster and easier to pass the 70 475 exam by using 70 475 exam. Immediate access to the exam 70 475 and find the same core area microsoft 70 475 with professionally verified answers, then PASS your exam with a high score now.
Free 70-475 Demo Online For Microsoft Certifitcation:
NEW QUESTION 1
A company named Fabrikam, Inc. plans to monitor financial markets and social networks, and then to correlate global stock movements to social network activity.
You need to recommend a Microsoft Azure HDInsight cluster solution that meets the following requirements:  Provides continuous availability
Provides continuous availability Can process asynchronous feeds
Can process asynchronous feeds
What is the best type of cluster to recommend to achieve the goal? More than one answer choice may achieve the goal. Select the BEST answer.
- A. Apache Hbase
- B. Apache Hadoop
- C. Apache Spark
- D. Apache Storm
Answer: C
NEW QUESTION 2
You are designing a data-driven data flow in Microsoft Azure Data Factory to copy data from Azure Blob storage to Azure SQL Database.
You need to create the copy activity.
How should you complete the JSON code? To answer, drag the appropriate code elements to the correct targets. Each element may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.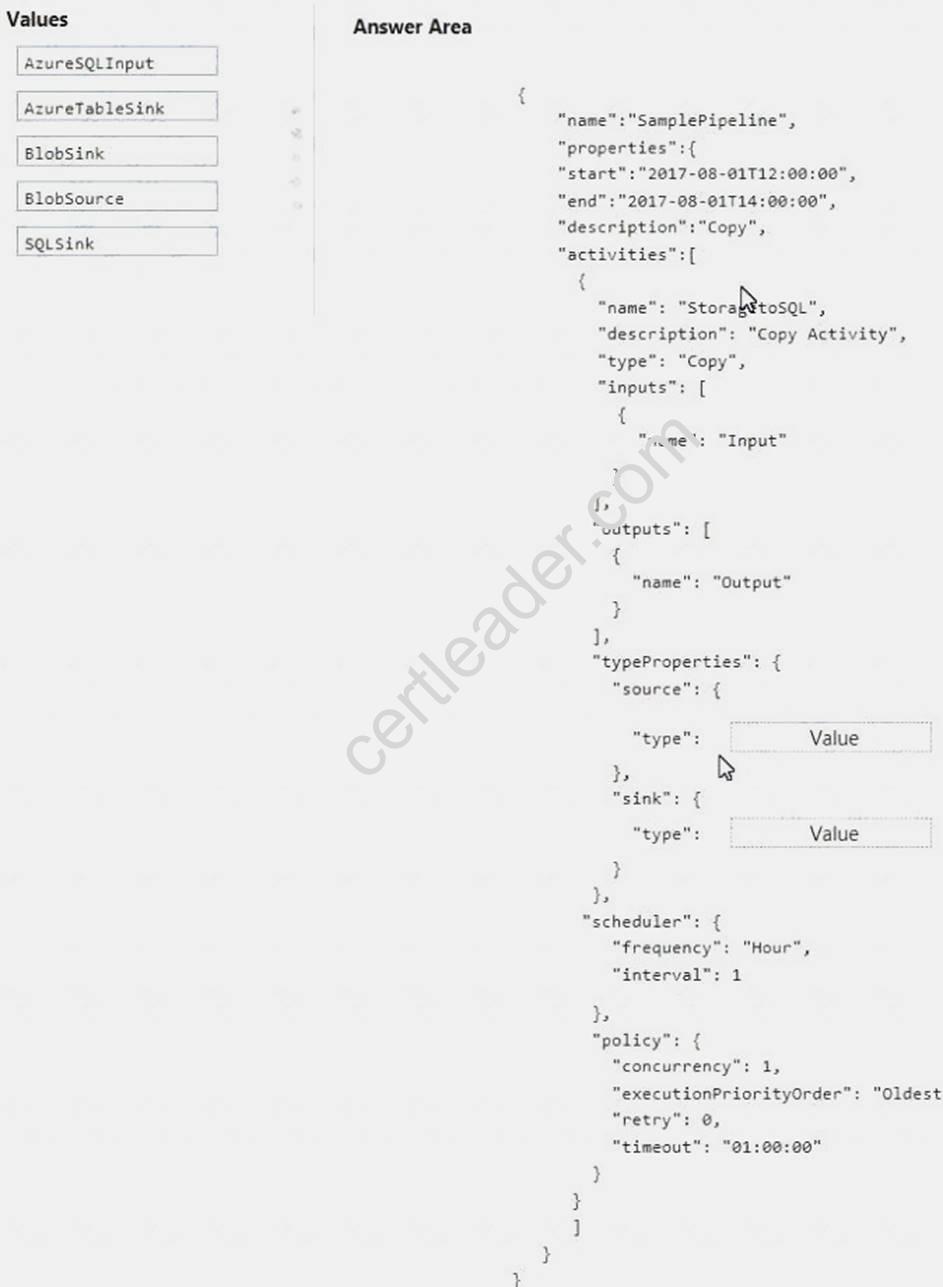
Answer:
Explanation: 
NEW QUESTION 3
You have structured data that resides in Microsoft Azure Blob Storage.
You need to perform a rapid interactive analysis of the data and to generate visualizations of the data.
What is the best type of Azure HDInsight cluster to use to achieve the goal? More than one answer choice may achieve the goal. Select the BEST answer.
- A. Apache Storm
- B. Apache HBase
- C. Apache Hadoop
- D. Apache Spark
Answer: D
Explanation:
Reference: https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-provision-linux-clusters
NEW QUESTION 4
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while the others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Microsoft Azure deployment that contains the following services:  Azure Data Lake Azure Cosmos DB Azure Data Factory Azure SQL Database
Azure Data Lake Azure Cosmos DB Azure Data Factory Azure SQL Database
You load several types of data to Azure Data Lake.
You need to load data from Azure SQL Database to Azure Data Lake. Solution: You use a stored procedure.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
Explanation: Note: You can use the Copy Activity in Azure Data Factory to copy data to and from Azure Data Lake Storage Gen1 (previously known as Azure Data Lake Store). Azure SQL database is supported as source.
References: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-data-lake-store
NEW QUESTION 5
You have data in an on-premises Microsoft SQL Server database.
You must ingest the data in Microsoft Azure Blob storage from the on-premises SQL Server database by using Azure Data Factory.
You need to identify which tasks must be performed from Azure.
In which sequence should you perform the actions? To answer, move all of the actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
Answer:
Explanation: Step 1: Configure a Microsoft Data Management Gateway Install and configure Azure Data Factory Integration Runtime.
The Integration Runtime is a customer managed data integration infrastructure used by Azure Data Factory to provide data integration capabilities across different network environments. This runtime was formerly called "Data Management Gateway".
Step 2: Create a linked service for Azure Blob storage
Create an Azure Storage linked service (destination/sink). You link your Azure storage account to the data factory.
Step 3: Create a linked service for SQL Server
Create and encrypt a SQL Server linked service (source)
In this step, you link your on-premises SQL Server instance to the data factory. Step 4: Create an input dataset and an output dataset.
Create a dataset for the source SQL Server database. In this step, you create input and output datasets. They represent input and output data for the copy operation, which copies data from the on-premises SQL Server database to Azure Blob storage.
Step 5: Create a pipeline..
You create a pipeline with a copy activity. The copy activity uses SqlServerDataset as the input dataset and AzureBlobDataset as the output dataset. The source type is set to SqlSource and the sink type is set to BlobSink.
References: https://docs.microsoft.com/en-us/azure/data-factory/tutorial-hybrid-copy-powershell
NEW QUESTION 6
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to deploy a Microsoft Azure SQL data warehouse and a web application.
The data warehouse will ingest 5 TB of data from an on-premises Microsoft SQL Server database daily. The web application will query the data warehouse.
You need to design a solution to ingest data into the data warehouse.
Solution: You use AzCopy to transfer the data as text files from SQL Server to Azure Blob storage, and then you use Azure Data Factory to refresh the data warehouse database.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 7
You work for a telecommunications company that uses Microsoft Azure Stream Analytics. You have data related to incoming calls.
You need to group the data in the following ways: Group A: Every five minutes for a duration of five minutes Group B: Every five minutes for a duration of 10 minutes
Which type of window should you use for each group? To answer, drag the appropriate window types to the correct groups. Each window type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: Group A: Tumbling
Tumbling Windows define a repeating, non-overlapping window of time. Group B: Hopping
Like Tumbling Windows, Hopping Windows move forward in time by a fixed period but they can overlap with one another.
NEW QUESTION 8
You plan to create a Microsoft Azure Data Factory pipeline that will connect to an Azure HDInsight cluster that uses Apache Spark.
You need to recommend which file format must be used by the pipeline. The solution must meet the following requirements: Store data in the columnar format Support compression
Which file format should you recommend?
- A. XML
- B. AVRO
- C. text
- D. Parquet
Answer: D
Explanation: Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
Apache Parquet supports compression.
NEW QUESTION 9
You have the following script.
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the script.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: A table created without the EXTERNAL clause is called a managed table because Hive manages its data.
NEW QUESTION 10
You have a Microsoft Azure Data Factory pipeline.
You discover that the pipeline fails to execute because data is missing. You need to rerun the failure in the pipeline.
Which cmdlet should you use?
- A. Set-AzureAutomationJob
- B. Resume-AzureDataFactoryPipeline
- C. Resume-AzureAutomationJob
- D. Set-AzureDataFactotySliceStatus
Answer: B
NEW QUESTION 11
Your company has several thousand sensors deployed.
You have a Microsoft Azure Stream Analytics job that receives two data streams Input1 and Input2 from an Azure event hub. The data streams are portioned by using a column named SensorName. Each sensor is identified by a field named SensorID.
You discover that Input2 is empty occasionally and the data from Input1 is ignored during the processing of the Stream Analytics job.
You need to ensure that the Stream Analytics job always processes the data from Input1.
How should you modify the query? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.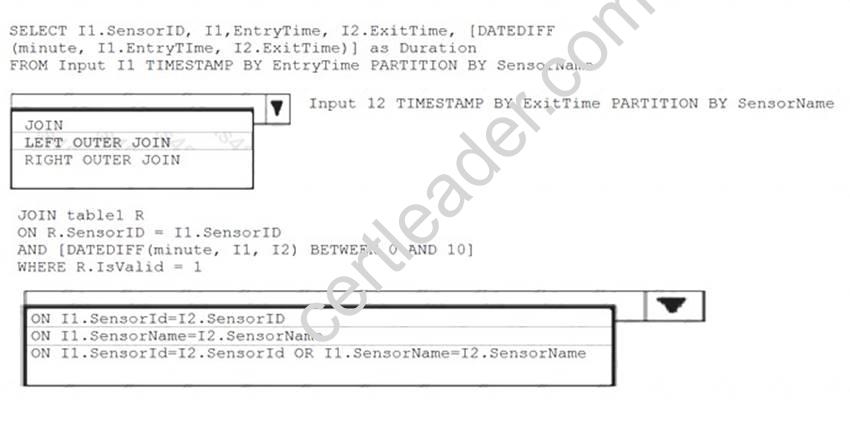
Answer:
Explanation: Box 1: LEFT OUTER JOIN
LEFT OUTER JOIN specifies that all rows from the left table not meeting the join condition are included in the result set, and output columns from the other table are set to NULL in addition to all rows returned by the inner join.
Box 2: ON I1.SensorID= I2.SensorID
References: https://docs.microsoft.com/en-us/stream-analytics-query/join-azure-stream-analytics
NEW QUESTION 12
You are automating the deployment of a Microsoft Azure Data Factory solution. The data factory will interact with a file stored in Azure Blob storage.
You need to use the REST API to create a linked service to interact with the file.
How should you complete the request body? To answer, drag the appropriate code elements to the correct locations. Each code may be used once, more than once, or not at all. You may need to drag the slit bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.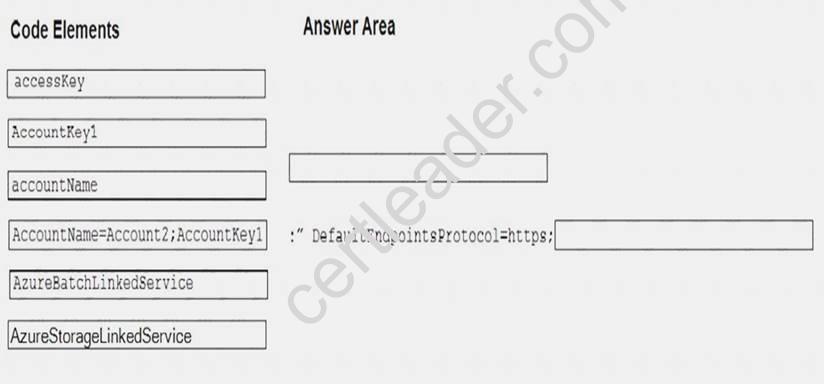
Answer:
Explanation: 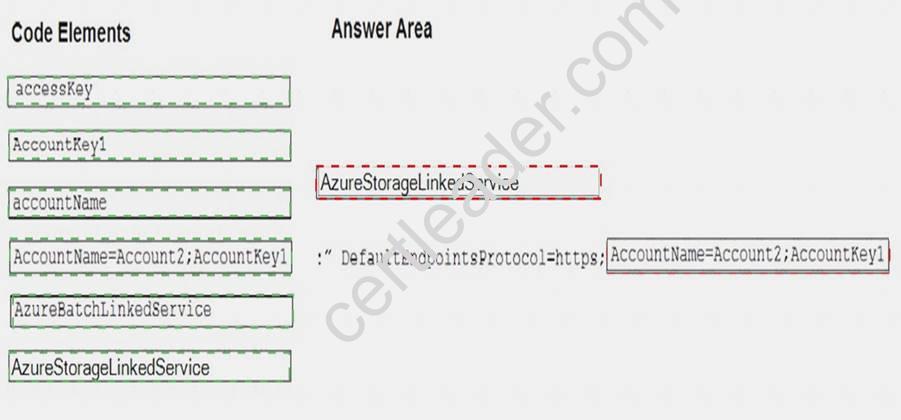
NEW QUESTION 13
Your company has 2000 servers.
You plan to aggregate all of the log files from the servers in a central repository that uses Microsoft Azure HDInsight. Each log file contains approximately one million records. All of the files use the .log file name extension.
The following is a sample of the entries in the log files.
20:26:41 SampleClass3 (ERROR) verbose detail for id 1527353937
In Apache Hive, you need to create a data definition and a query capturing tire number of records that have an error level of [ERROR].
What should you do? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.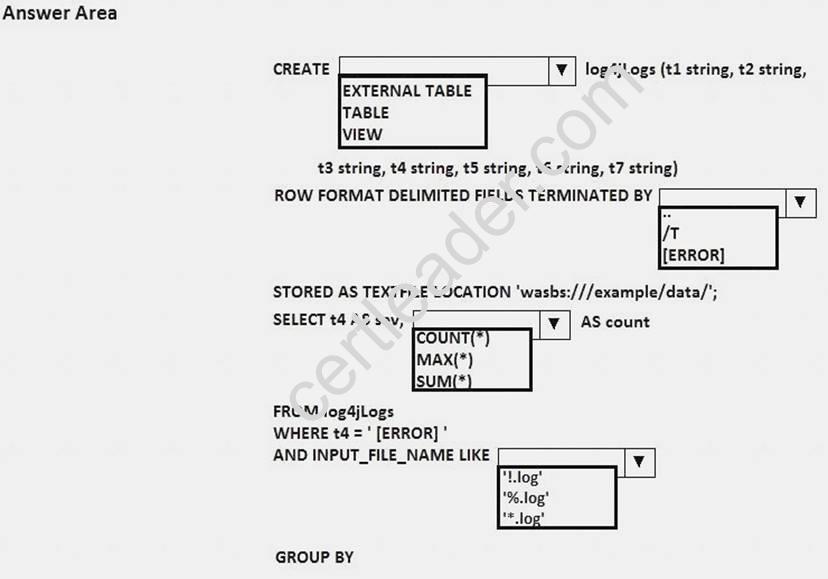
Answer:
Explanation: Box 1: table
Box 2: /t
Apache Hive example:
CREATE TABLE raw (line STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY 't' LINES TERMINATED BY 'n';
Box 3: count(*)
Box 4: '*.log'
NEW QUESTION 14
You have a web app that accepts user input, and then uses a Microsoft Azure Machine Learning model to predict a characteristic of the user.
You need to perform the following operations: Track the number of web app users from month to month. Track the number of successful predictions made during the last minute. Create a dashboard showcasing the analytics tor the predictions and the web app usage.
Which lambda layer should you query for each operation? To answer, drag the appropriate layers to the correct operations. Each layer may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation
Box 1: Speed
The speed layer processes data streams in real time and without the requirements of fix-ups or completeness. This layer sacrifices throughput as it aims to minimize latency by providing real-time views into the most recent data.
Box 2: Batch
The batch layer precomputes results using a distributed processing system that can handle very large quantities of data. The batch layer aims at perfect accuracy by being able to process all available data when generating views.
Box 3: Serving
Output from the batch and speed layers are stored in the serving layer, which responds to ad-hoc queries by returning precomputed views or building views from the processed data.
NEW QUESTION 15
You have a Microsoft Azure Data Factory pipeline.
You discover that the pipeline fails to execute because data is missing. You need to rerun the failure in the pipeline.
Which cmdlet should you use?
- A. Set-AzureRmAutomationJob
- B. Set-AzureRmDataFactorySliceStatus
- C. Resume-AzureRmDataFactoryPipeline
- D. Resume-AzureRmAutomationJob
Answer: B
Explanation: Use some PowerShell to inspect the ADF activity for the missing file error. Then simply set the dataset slice to either skipped or ready using the cmdlet to override the status.
For example:
Set-AzureRmDataFactorySliceStatus `
-ResourceGroupName $ResourceGroup `
-DataFactoryName $ADFName.DataFactoryName `
-DatasetName $Dataset.OutputDatasets `
-StartDateTime $Dataset.WindowStart `
-EndDateTime $Dataset.WindowEnd `
-Status "Ready" `
-UpdateType "Individual" References:
https://stackoverflow.com/questions/42723269/azure-data-factory-pipelines-are-failing-when-no-files-available-
NEW QUESTION 16
You plan to implement a Microsoft Azure Data Factory pipeline. The pipeline will have custom business logic that requires a custom processing step.
You need to implement the custom processing step by using C#.
Which interface and method should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.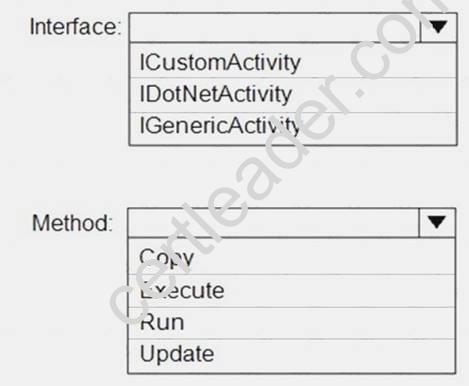
Answer:
Explanation: References:
https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/data-factory/v1/data-factory-use-custom-activ
NEW QUESTION 17
You have data generated by sensors. The data is sent to Microsoft Azure Event Hubs.
You need to have an aggregated view of the data in near real-time by using five minute tumbling windows to identity short-term trends. You must also have hourly and a daily aggregated views of the data.
Which technology should you use for each task? To answer, drag the appropriate technologies to the correct tasks. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: Box 1: Azure HDInsight MapReduce
Azure Event Hubs allows you to process massive amounts of data from websites, apps, and devices. The Event Hubs spout makes it easy to use Apache Storm on HDInsight to analyze this data in real time.
Box 2: Azure Event Hub
Box 3: Azure Stream Analytics
Stream Analytics is a new service that enables near real time complex event processing over streaming data. Combining Stream Analytics with Azure Event Hubs enables near real time processing of millions of events per second. This enables you to do things such as augment stream data with reference data and output to storage (or even output to another Azure Event Hub for additional processing).
NEW QUESTION 18
You need to recommend a platform architecture for a big data solution that meets the following requirements: Supports batch processing
Provides a holding area for a 3-petabyte (PB) dataset
Minimizes the development effort to implement the solution
Provides near real time relational querying across a multi-terabyte (TB) dataset
Which two platform architectures should you include in the recommendation? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. a Microsoft Azure SQL data warehouse
- B. a Microsoft Azure HDInsight Hadoop cluster
- C. a Microsoft SQL Server database
- D. a Microsoft Azure HDInsight Storm cluster
- E. Microsoft Azure Table Storage
Answer: AE
Explanation: A: Azure SQL Data Warehouse is a SQL-based, fully-managed, petabyte-scale cloud data warehouse. It’s highly elastic, and it enables you to set up in minutes and scale capacity in seconds. Scale compute and storage independently, which allows you to burst compute for complex analytical workloads, or scale down your warehouse for archival scenarios, and pay based on what you're using instead of being locked into predefined cluster configurations—and get more cost efficiency versus traditional data warehouse solutions.
E: Use Azure Table storage to store petabytes of semi-structured data and keep costs down. Unlike many data stores—on-premises or cloud-based—Table storage lets you scale up without having to manually shard your dataset. Perform OData-based queries.
P.S. 2passeasy now are offering 100% pass ensure 70-475 dumps! All 70-475 exam questions have been updated with correct answers: https://www.2passeasy.com/dumps/70-475/ (102 New Questions)