A Review Of Exact DP-201 Preparation
Certleader DP-201 Questions are updated and all DP-201 answers are verified by experts. Once you have completely prepared with our DP-201 exam prep kits you will be ready for the real DP-201 exam without a problem. We have Abreast of the times Microsoft DP-201 dumps study guide. PASSED DP-201 First attempt! Here What I Did.
Free DP-201 Demo Online For Microsoft Certifitcation:
NEW QUESTION 1
You need to design the runtime environment for the Real Time Response system. What should you recommend?
- A. General Purpose nodes without the Enterprise Security package
- B. Memory Optimized Nodes without the Enterprise Security package
- C. Memory Optimized nodes with the Enterprise Security package
- D. General Purpose nodes with the Enterprise Security package
Answer: B
NEW QUESTION 2
You are designing an Azure SQL Data Warehouse. You plan to load millions of rows of data into the data warehouse each day.
You must ensure that staging tables are optimized for data loading. You need to design the staging tables.
What type of tables should you recommend?
- A. Round-robin distributed table
- B. Hash-distributed table
- C. Replicated table
- D. External table
Answer: A
Explanation:
To achieve the fastest loading speed for moving data into a data warehouse table, load data into a staging table. Define the staging table as a heap and use round-robin for the distribution option.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/guidance-for-loading-data
NEW QUESTION 3
A company is developing a mission-critical line of business app that uses Azure SQL Database Managed Instance. You must design a disaster recovery strategy for the solution.
You need to ensure that the database automatically recovers when full or partial loss of the Azure SQL Database service occurs in the primary region.
What should you recommend?
- A. Failover-group
- B. Azure SQL Data Sync
- C. SQL Replication
- D. Active geo-replication
Answer: A
Explanation:
Auto-failover groups is a SQL Database feature that allows you to manage replication and failover of a group of databases on a SQL Database server or all databases in a Managed Instance to another region (currently in public preview for Managed Instance). It uses the same underlying technology as active geo-replication. You can initiate failover manually or you can delegate it to the SQL Database service based on a user-defined policy.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-auto-failover-group
NEW QUESTION 4
You are developing a solution that performs real-time analysis of IoT data in the cloud. The solution must remain available during Azure service updates.
You need to recommend a solution.
Which two actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Deploy an Azure Stream Analytics job to two separate regions that are not in a pair.
- B. Deploy an Azure Stream Analytics job to each region in a paired region.
- C. Monitor jobs in both regions for failure.
- D. Monitor jobs in the primary region for failure.
- E. Deploy an Azure Stream Analytics job to one region in a paired region.
Answer: BC
Explanation:
Stream Analytics guarantees jobs in paired regions are updated in separate batches. As a result there is a sufficient time gap between the updates to identify potential breaking bugs and remediate them.
Customers are advised to deploy identical jobs to both paired regions.
In addition to Stream Analytics internal monitoring capabilities, customers are also advised to monitor the jobs as if both are production jobs. If a break is identified to be a result of the Stream Analytics service update, escalate appropriately and fail over any downstream consumers to the healthy job output. Escalation to support will prevent the paired region from being affected by the new deployment and maintain the integrity of the paired jobs.
References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-job-reliability
NEW QUESTION 5
A company has an application that uses Azure SQL Database as the data store.
The application experiences a large increase in activity during the last month of each year.
You need to manually scale the Azure SQL Database instance to account for the increase in data write operations.
Which scaling method should you recommend?
- A. Scale up by using elastic pools to distribute resources.
- B. Scale out by sharding the data across databases.
- C. Scale up by increasing the database throughput units.
Answer: C
Explanation:
As of now, the cost of running an Azure SQL database instance is based on the number of Database Throughput Units (DTUs) allocated for the database. When determining the number of units to allocate for the
solution, a major contributing factor is to identify what processing power is needed to handle the volume of expected requests.
Running the statement to upgrade/downgrade your database takes a matter of seconds.
NEW QUESTION 6
You are designing a Spark job that performs batch processing of daily web log traffic.
When you deploy the job in the production environment, it must meet the following requirements:  Run once a day. Display status information on the company intranet as the job runs. You need to recommend technologies for triggering and monitoring jobs.
Run once a day. Display status information on the company intranet as the job runs. You need to recommend technologies for triggering and monitoring jobs.
Which technologies should you recommend? To answer, drag the appropriate technologies to the correct locations. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.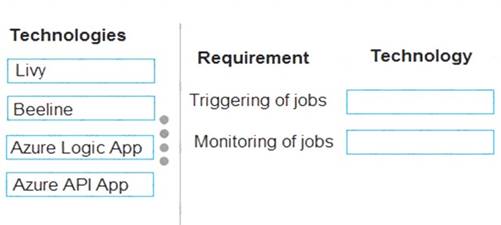
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Livy
You can use Livy to run interactive Spark shells or submit batch jobs to be run on Spark. Box 2: Beeline
Apache Beeline can be used to run Apache Hive queries on HDInsight. You can use Beeline with Apache Spark.
Note: Beeline is a Hive client that is included on the head nodes of your HDInsight cluster. Beeline uses JDBC to connect to HiveServer2, a service hosted on your HDInsight cluster. You can also use Beeline to access Hive on HDInsight remotely over the internet.
References:
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-livy-rest-interface https://docs.microsoft.com/en-us/azure/hdinsight/hadoop/apache-hadoop-use-hive-beeline
NEW QUESTION 7
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will use Azure SQL Data Warehouse as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Create a user-defined restore point before data is uploaded. Delete the restore point after data corruption checks complete.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: A
Explanation:
User-Defined Restore Points
This feature enables you to manually trigger snapshots to create restore points of your data warehouse before and after large modifications. This capability ensures that restore points are logically consistent, which provides additional data protection in case of any workload interruptions or user errors for quick recovery time.
Note: A data warehouse restore is a new data warehouse that is created from a restore point of an existing or deleted data warehouse. Restoring your data warehouse is an essential part of any business continuity and disaster recovery strategy because it re-creates your data after accidental corruption or deletion.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
NEW QUESTION 8
You need to recommend a solution for storing the image tagging data. What should you recommend?
- A. Azure File Storage
- B. Azure Cosmos DB
- C. Azure Blob Storage
- D. Azure SQL Database
- E. Azure SQL Data Warehouse
Answer: C
Explanation:
Image data must be stored in a single data store at minimum cost.
Note: Azure Blob storage is Microsoft's object storage solution for the cloud. Blob storage is optimized for storing massive amounts of unstructured data. Unstructured data is data that does not adhere to a particular data model or definition, such as text or binary data.
Blob storage is designed for: Serving images or documents directly to a browser. Storing files for distributed access. Streaming video and audio. Writing to log files. Storing data for backup and restore, disaster recovery, and archiving. Storing data for analysis by an on-premises or Azure-hosted service.
Serving images or documents directly to a browser. Storing files for distributed access. Streaming video and audio. Writing to log files. Storing data for backup and restore, disaster recovery, and archiving. Storing data for analysis by an on-premises or Azure-hosted service.
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blobs-introduction
NEW QUESTION 9
STION NO: 5 HOTSPOT
You need to design the authentication and authorization methods for sensors.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Sensor data must be stored in a Cosmos DB named treydata in a collection named SensorData Sensors must have permission only to add items to the SensorData collection
Box 1: Resource Token
Resource tokens provide access to the application resources within a Cosmos DB database.
Enable clients to read, write, and delete resources in the Cosmos DB account according to the permissions they've been granted.
Box 2: Cosmos DB user
You can use a resource token (by creating Cosmos DB users and permissions) when you want to provide access to resources in your Cosmos DB account to a client that cannot be trusted with the master key.
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/secure-access-to-data
NEW QUESTION 10
HOTSPOT
You need to ensure that security policies for the unauthorized detection system are met. What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Blob storage
Configure blob storage for audit logs.
Scenario: Unauthorized usage of the Planning Assistance data must be detected as quickly as possible. Unauthorized usage is determined by looking for an unusual pattern of usage.
Data used for Planning Assistance must be stored in a sharded Azure SQL Database. Box 2: Web Apps
SQL Advanced Threat Protection (ATP) is to be used.
One of Azure’s most popular service is App Service which enables customers to build and host web applications in the programming language of their choice without managing infrastructure. App Service offers auto-scaling and high availability, supports both Windows and Linux. It also supports automated deployments from GitHub, Visual Studio Team Services or any Git repository. At RSA, we announced that Azure Security Center leverages the scale of the cloud to identify attacks targeting App Service applications.
References:
https://azure.microsoft.com/sv-se/blog/azure-security-center-can-identify-attacks-targeting-azure-app-service-ap
NEW QUESTION 11
A company purchases loT devices to monitor manufacturing machinery. The company uses an loT appliance to communicate with the loT devices.
The company must be able to monitor the devices in real-time. You need to design the solution.
What should you recommend?
- A. Azure Stream Analytics cloud job using Azure PowerShell
- B. Azure Analysis Services using Azure Portal
- C. Azure Data Factory instance using Azure Portal
- D. Azure Analysis Services using Azure PowerShell
Answer: D
NEW QUESTION 12
You need to design the vehicle images storage solution. What should you recommend?
- A. Azure Media Services
- B. Azure Premium Storage account
- C. Azure Redis Cache
- D. Azure Cosmos DB
Answer: B
Explanation:
Premium Storage stores data on the latest technology Solid State Drives (SSDs) whereas Standard Storage stores data on Hard Disk Drives (HDDs). Premium Storage is designed for Azure Virtual Machine workloads which require consistent high IO performance and low latency in order to host IO intensive workloads like OLTP, Big Data, and Data Warehousing on platforms like SQL Server, MongoDB, Cassandra, and others. With Premium Storage, more customers will be able to lift-and-shift demanding enterprise applications to the cloud.
Scenario: Traffic sensors will occasionally capture an image of a vehicle for debugging purposes. You must optimize performance of saving/storing vehicle images.
The impact of vehicle images on sensor data throughout must be minimized. References:
https://azure.microsoft.com/es-es/blog/introducing-premium-storage-high-performance-storage-for-azure-virtual
NEW QUESTION 13
You need to design the Planning Assistance database.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: No
Data used for Planning Assistance must be stored in a sharded Azure SQL Database. Box 2: Yes
Box 3: Yes
Planning Assistance database will include reports tracking the travel of a single vehicle
NEW QUESTION 14
You need to design the SensorData collection.
What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.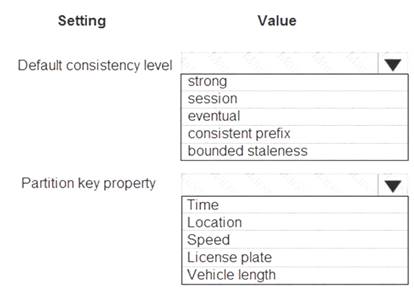
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Eventual
Traffic data insertion rate must be maximized.
Sensor data must be stored in a Cosmos DB named treydata in a collection named SensorData
With Azure Cosmos DB, developers can choose from five well-defined consistency models on the consistency spectrum. From strongest to more relaxed, the models include strong, bounded staleness, session, consistent prefix, and eventual consistency.
Box 2: License plate
This solution reports on all data related to a specific vehicle license plate. The report must use data from the SensorData collection.
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels
NEW QUESTION 15
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure SQL Database that will use elastic pools. You plan to store data about customers in a table. Each record uses a value for CustomerID.
You need to recommend a strategy to partition data based on values in CustomerID. Proposed Solution: Separate data into shards by using horizontal partitioning.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: A
Explanation:
Horizontal Partitioning - Sharding: Data is partitioned horizontally to distribute rows across a scaled out data
tier. With this approach, the schema is identical on all participating databases. This approach is also called “sharding”. Sharding can be performed and managed using (1) the elastic database tools libraries or (2) selfsharding.
An elastic query is used to query or compile reports across many shards. References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-query-overview
NEW QUESTION 16
You need to design the encryption strategy for the tagging data and customer data.
What should you recommend? To answer, drag the appropriate setting to the correct drop targets. Each source may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.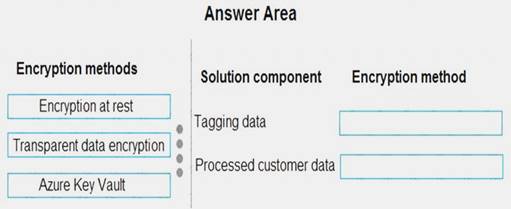
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
All cloud data must be encrypted at rest and in transit. Box 1: Transparent data encryption
Encryption of the database file is performed at the page level. The pages in an encrypted database are encrypted before they are written to disk and decrypted when read into memory.
Box 2: Encryption at rest
Encryption at Rest is the encoding (encryption) of data when it is persisted. References:
https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/transparent-data-encryption?view= https://docs.microsoft.com/en-us/azure/security/azure-security-encryption-atrest
NEW QUESTION 17
You are evaluating data storage solutions to support a new application.
You need to recommend a data storage solution that represents data by using nodes and relationships in graph structures.
Which data storage solution should you recommend?
- A. Blob Storage
- B. Cosmos DB
- C. Data Lake Store
- D. HDInsight
Answer: B
Explanation:
For large graphs with lots of entities and relationships, you can perform very complex analyses very quickly. Many graph databases provide a query language that you can use to traverse a network of relationships efficiently.
Relevant Azure service: Cosmos DB
References:
https://docs.microsoft.com/en-us/azure/architecture/guide/technology-choices/data-store-overview
NEW QUESTION 18
You are designing a data processing solution that will run as a Spark job on an HDInsight cluster. The solution will be used to provide near real-time information about online ordering for a retailer.
The solution must include a page on the company intranet that displays summary information. The summary information page must meet the following requirements: Display a summary of sales to date grouped by product categories, price range, and review scope. Display sales summary information including total sales, sales as compared to one day ago and sales as compared to one year ago. Reflect information for new orders as quickly as possible. You need to recommend a design for the solution.
Display a summary of sales to date grouped by product categories, price range, and review scope. Display sales summary information including total sales, sales as compared to one day ago and sales as compared to one year ago. Reflect information for new orders as quickly as possible. You need to recommend a design for the solution.
What should you recommend? To answer, select the appropriate configuration in the answer area.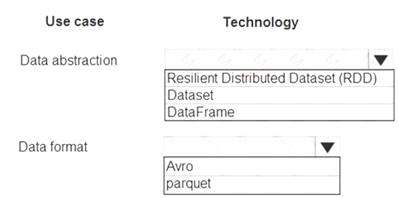
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: DataFrame
DataFrames
Best choice in most situations.
Provides query optimization through Catalyst. Whole-stage code generation.
Direct memory access.
Low garbage collection (GC) overhead.
Not as developer-friendly as DataSets, as there are no compile-time checks or domain object programming. Box 2: parquet
The best format for performance is parquet with snappy compression, which is the default in Spark 2.x. Parquet stores data in columnar format, and is highly optimized in Spark.
NEW QUESTION 19
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The
solution will use Azure SQL Data Warehouse as the data store. Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Insert data from shops and perform the data corruption check in a transaction. Rollback transfer if corruption is detected.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Instead, create a user-defined restore point before data is uploaded. Delete the restore point after data corruption checks complete.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
NEW QUESTION 20
A company manufactures automobile parts. The company installs IoT sensors on manufacturing machinery. You must design a solution that analyzes data from the sensors.
You need to recommend a solution that meets the following requirements: Data must be analyzed in real-time.
Data queries must be deployed using continuous integration. Data must be visualized by using charts and graphs.
Data must be available for ETL operations in the future. The solution must support high-volume data ingestion.
Which three actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Use Azure Analysis Services to query the dat
- B. Output query results to Power BI.
- C. Configure an Azure Event Hub to capture data to Azure Data Lake Storage.
- D. Develop an Azure Stream Analytics application that queries the data and outputs to Power B
- E. Use AzureData Factory to deploy the Azure Stream Analytics application.
- F. Develop an application that sends the IoT data to an Azure Event Hub.
- G. Develop an Azure Stream Analytics application that queries the data and outputs to Power B
- H. Use AzurePipelines to deploy the Azure Stream Analytics application.
- I. Develop an application that sends the IoT data to an Azure Data Lake Storage container.
Answer: BCD
NEW QUESTION 21
You are designing a real-time stream solution based on Azure Functions. The solution will process data uploaded to Azure Blob Storage.
The solution requirements are as follows:
New blobs must be processed with a little delay as possible. Scaling must occur automatically.
Costs must be minimized. What should you recommend?
- A. Deploy the Azure Function in an App Service plan and use a Blob trigger.
- B. Deploy the Azure Function in a Consumption plan and use an Event Grid trigger.
- C. Deploy the Azure Function in a Consumption plan and use a Blob trigger.
- D. Deploy the Azure Function in an App Service plan and use an Event Grid trigger.
Answer: C
Explanation:
Create a function, with the help of a blob trigger template, which is triggered when files are uploaded to or updated in Azure Blob storage.
You use a consumption plan, which is a hosting plan that defines how resources are allocated to your function app. In the default Consumption Plan, resources are added dynamically as required by your functions. In this serverless hosting, you only pay for the time your functions run. When you run in an App Service plan, you must manage the scaling of your function app.
References:
https://docs.microsoft.com/en-us/azure/azure-functions/functions-create-storage-blob-triggered-function
NEW QUESTION 22
......
P.S. Easily pass DP-201 Exam with 74 Q&As 2passeasy Dumps & pdf Version, Welcome to Download the Newest 2passeasy DP-201 Dumps: https://www.2passeasy.com/dumps/DP-201/ (74 New Questions)